
Parser-based analysis and clustering for Avaloq scripts
Parser-based analysis and clustering for Avaloq scripts
As part of our Bachelor’s thesis in Computer Science (Bachelor of Applied Science), my colleague and I analyzed Avaloq scripts within the Avaloq core banking system of our client to investigate how similar various scripts are to one another. We applied several approaches and tools to automatically analyze and compare these scripts. A central element of this work was developing a custom Avaloq script parser that enabled the creation of syntax trees, which were then used for analysis and comparison. More on that below.
What is Avaloq and Avaloq Script?
Avaloq is a core banking system developed in Switzerland and used by our client and numerous banks and financial institutions worldwide. It provides a comprehensive software solution for managing financial services such as account management, payments, wealth management, compliance, and reporting. In addition to offering core business functionality, Avaloq also serves as a data source and provides data for various applications.
Functions, application-masks (GUIs), and reports in Avaloq are developed using its proprietary programming language called Avaloq Script, which is based on PL/SQL and, in simplified terms, is translated into PL/SQL after compilation.
Further information can be found in the official Avaloq documentation.
Objective and Purporse
In the client’s Avaloq system, there are several thousand scripts tailored to numerous business processes and use cases. Over the years, this number has grown substantially, leading to significant maintenance and operational overhead. It is known that some scripts are similar in their purpose or logic and could potentially be merged. However, the number of such scripts and which ones can be grouped is not known.
The goal of this thesis was to develop an analysis tool that systematically analyzes Avaloq scripts, compares them, detects overlaps, and visualizes the results in a clear and intuitive way. The analysis results should reveal, for example, which scripts use the same data sources or implement identical or similar logic. The analysis considers not only syntactic equality (e.g., identical code) but also semantic similarity to uncover functional commonalities.
Approach
The work is divided into the following steps:
- Develop a parser for Avaloq Script and generate syntax trees
- Analyze the syntax trees
- Group and cluster the scripts
Parser and Syntax Tree
The parser was built using ANTLR , a widely used tool for generating parsers for various programming languages. ANTLR allows defining a formal grammar of the language and automatically generates a parser from it. This makes it possible to analyze all scripts consistently and transform them into structured syntax trees.
Syntax trees are a tree-like representation of a script’s syntactic structure, where each node represents a language construct (e.g., statements, expressions, control structures). This structured form significantly facilitates the analysis and comparison of scripts.
Analyzing Syntax Trees
In collaboration with the client’s staff, relevant features for script comparison were identified and extracted from the syntax trees. For example, data sources and referenced columns were identified, allowing for an initial pre-grouping of the scripts.
For further analysis of the syntax trees, the Tree Edit Distance (TED) algorithm was used, an algorithm that measures the similarity between two trees. It calculates the minimum number of operations (insertions, deletions, substitutions) required to transform one tree into another. The fewer operations needed, the more similar the two trees are.
Grouping and Clustering Scripts
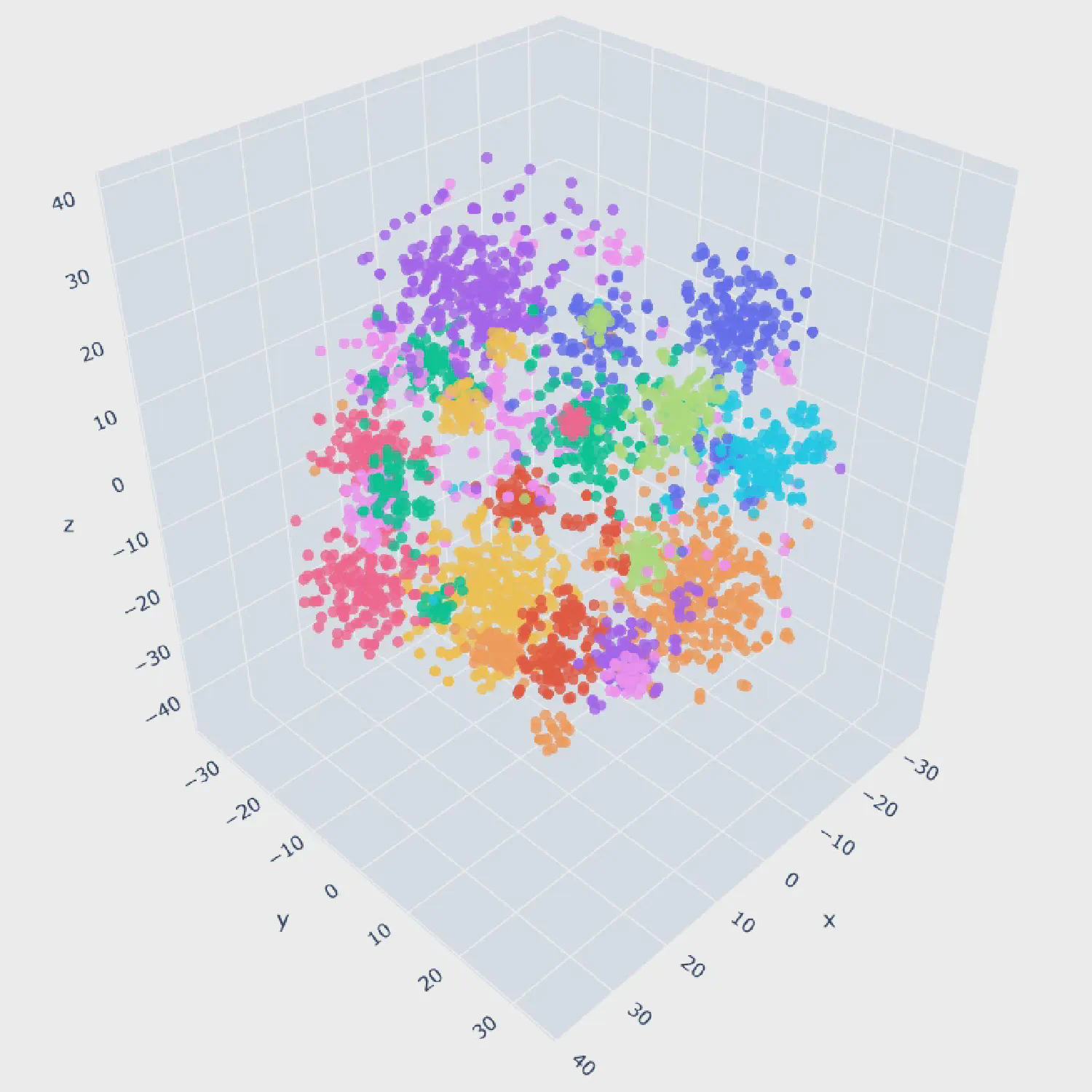
To group similar scripts, clustering methods were applied — specifically an attraction-repulsion clustering approach and the k-Means algorithm. The clustering results can be visualized in 2D and 3D, where similar scripts appear close together and dissimilar ones are farther apart.
Example:
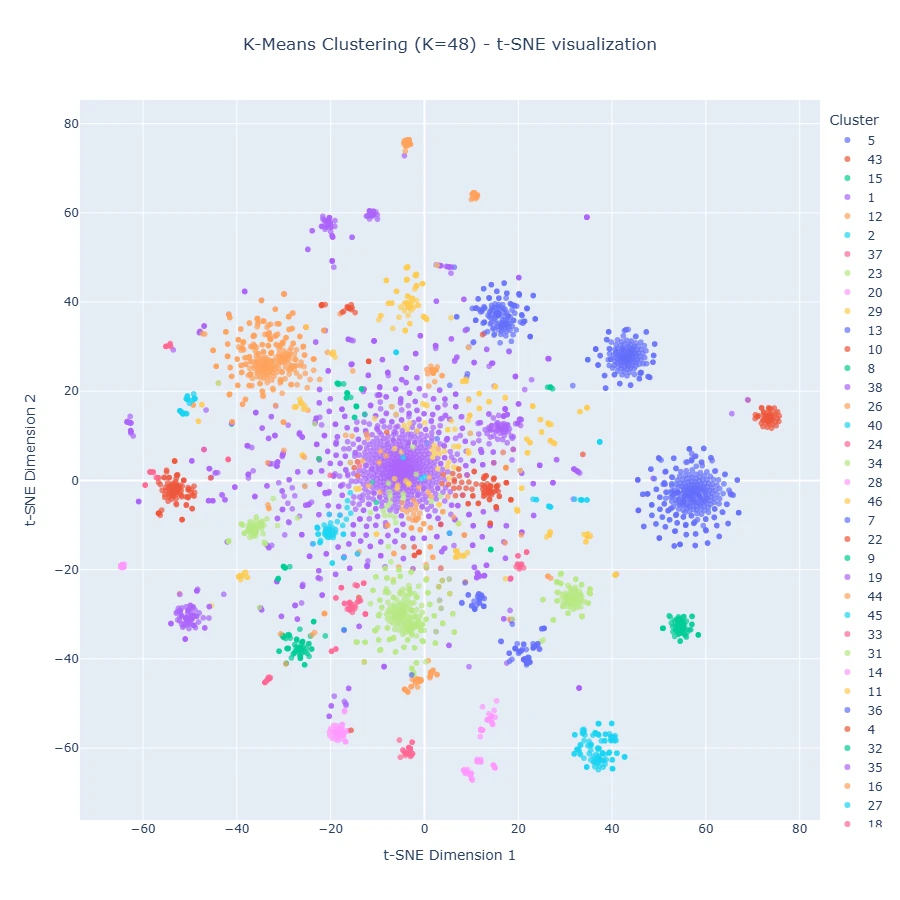
This 2D-visualization shows clearly distinguishable clusters of similar scripts (high density, well separated), as well as clusters containing more dispersed scripts. The image at the top of the page shows the same clustering in a three dimensional view.
Results
A working parser was successfully developed and applied to generate syntax trees. It was also possible to identify relevant features of Avaloq scripts that are representative of script similarity. Based on these, similar scripts could be grouped using clustering techniques, including the display of similarity values.
With these results, the client can now automatically identify scripts suitable for potential refactoring. It is also possible to find scripts based on the data sources and fields they use, which is particularly helpful for release upgrades. Moreover, domain-relevant features can be extracted from script clusters, which can be used for providing or exporting data to a data lake (data warehouse), among other use cases.
Further Information
Additional details and data are reserved for the client. For questions, feedback, or interest in this project, feel free to contact me via the contact form contact form .
Disclaimer: Avaloq and Avaloq Script are registered trademarks and proprietary technologies of Avaloq Group AG.